This webpage introduces vinci and gives a brief portrayal of its wide range of capabilities. The various parts are fleshed out in the Manual pages.
vinci has been used primarily as an experimental tool, for testing linguistic theories, for exploring the limits of natural language generation, for investigating computer-aided language learning, for testing students and, in some cases, for actual language teaching. At its fullest extent, vinci is complex and very powerful. In its basic form, it is fairly easy to grasp and to use.
The primary function of the vinci system is to generate utterances in some language, either natural or artificial, which a user defines (called the object language). A secondary function is to transform parts of the object language lexicon to create new words, based on rules known as lexical transformations. The files which define the object language constitute a metalanguage, or perhaps more accurately, a set of metalanguages. These files and their notation will be described in the Manual pages.
The vinci system is embedded as a collection of operations within the ivi Editor. Thus, ivi provides a vehicle for receiving and carrying out these operations, at the same time offering facilities to create and modify the vinci language-description files, and to display, edit and save the results of utterance generation.
(The sections of the Manual describing vinci commands and operations assume that the reader has some familiarity with ivi, which is described elsewhere in these webpages.)
In the interests of simplicity, we will hereafter use the term sentence for any utterance, whether it is technically a sentence or not; also, we will often use the term word for any item which appears in a lexicon, even if the item is an idiomatic phrase, a prefix or some other object-language component.
Simple Generation
In its simplest use, vinci is given files which define a language and specify the kind of sentence required. Generation begins with syntax and starts with a ROOT rule. Consider, for example, the syntax rules below. (Note to linguists: this is not a typical representation of a sentence tree. It is used here for simplicity and to bring together in one place a collection of devices offered by vinci syntax.)
ROOT = NP V[vtdi] NP PREP/"to" NP %
NP = DET N %
Ignoring for a moment the elements [vtdi] and /"to", we see here two rules, one for ROOT, the other for NP, telling vinci how to construct a syntax tree. The first states that the ROOT node of the tree has five child nodes: NP, V, NP, PREP and NP; the second, that each NP node has two children: DET and N. (The symbol = is to be read "has the children", or using formal terminology: "may be rewritten as".) The syntax yields a tree of the shape:
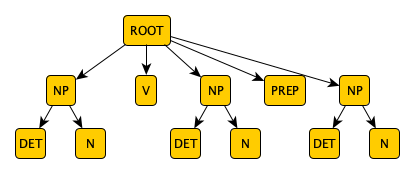
The names of the tree nodes: NP, DET, N, V and PREP are called metavariables, and are chosen by the person writing the syntax. The last four have no rules to develop them further, and therefore become leaf nodes of the tree. For generation to be successful, these must correspond to entries in the lexicon. In this example, DET, N, V and PREP probably refer to determiner, noun, verb and preposition, and NP to a simple form of noun phrase.
The attachment [vtdi] is an attribute list which, among other things, restricts the choice of V to words of category V having vtdi as one of its attribute values. In our lexicons, we use this to indicate verbs which require both direct and indirect objects. The attachment /"to" is a mandated choice, requiring vinci to choose "to" as the PREP. vinci is therefore being asked to generate simple sentences having both a direct and an indirect object.
Wherever vinci has a choice among syntax structures or among words in the lexicon, it chooses at random. Later on, we shall see how to restrict these choices more and more, until we get to the point where vinci constructs sentences dependent on their intended meaning. This, however, involves some of the deeper vinci features.
With the syntax above, vinci may generate:
the professor gives a book to the student
and:
the fish recommends a cousin to the hostess
and so on, including sentences which are correct grammatically but perhaps rather strange semantically.
The Syntax
Stripped of their attachments, the syntax rules shown above constitute a Chomsky context-free phrase structure grammar, and it is such a grammar which forms the basis of all vinci syntax. The syntax permits alternative structures. If we want to introduce the possibility of single adjectives, the second rule might be replaced by:
NP = (DET N | DET ADJ N) %
where | separates alternatives, and the alternative sections are enclosed in parentheses. Such right-hand sides may even be "factorized" in a way which reminds us of algebraic factorization:
NP = DET ( | ADJ) N %
Comments: Readers familiar with Chomsky's formulation or its programming language equivalent, Backus-Naur form, will notice some differences in form, though not in scope:
- The syntax terminates one level above the actual words of the object language. This last level is filled by reference to a lexicon. (Otherwise the rule for replacing N might contain 10,000 alternatives!)
- Alternatives, even those not "factorized", must be embedded in parentheses.
- Empty alternatives may be included. But beware of rules in the form: P = (Q | )(R | ) %, where choosing both empty alternatives will leave P with no children, making it a presumably unintended leaf node. This in turn will lead to an error when the lexicon search reveals no entries for P.
Attributes
Attributes carry grammatical and semantic information, and play a key role in many parts of vinci. We will give only a glimpse here, leaving a fuller description to the Manual.
Attributes are grouped into types, each consisting of a set of values. Types and values are specified by the person defining the language. A typical example might be a type Number containing two values: sing and plur. We emphasize that the names themselves have no implicit meaning; their significance depends only on the way the language definition uses them. In this case, it would be user-friendly if sing and plur carried information about the grammatical number of components such as nouns, noun phrases and verbs. It would be decidedly user-hostile, but quite legal, if they represented gender.
Consider once again the tiny syntax given earlier:
ROOT = NP V[vtdi] NP PREP/"to" NP %
NP = DET N %
Unless we have restricted the lexicon to singular nouns and verbs, this generates not only the grammatical sentences shown above, but also:
the professors gives a books to the student
Nothing constrains the subject of the sentence to agree with the verb, or the determiner of a noun phrase to agree with its noun.
The latter effect can be achieved quite simply with the help of the attribute type just specified. We can replace the second rule with:
NP = (DET[sing] N[sing] | DET[plur] N[plur]) %
assuming that the lexical entry for the DET "a" has sing as one of its attribute values, while "the" has both sing and plur; entries for "book", "professor", ... must also have sing, those for "books", ... plur.
Agreement between the subject NP and V is more awkward, because attaching sing or plur to both NP and V in the first rule does not force vinci to choose the correct alternative in the second. This can be done with the features already described; the reader is invited to work out how. (Hint: the NP rule should be replaced with rules for NPSING and NPPLUR. The ROOT rule requires several alternatives.) However, it is much simpler to use choose and inherit clauses. (See below).
Attributes can also carry semantic information. For example, we may have the attribute type Nountrait with values human, animate, edible, ... A verb such as "eat" may be then constrained to have an animate subject and an edible direct object.
Choose and Inherit Clauses
Choose and inherit clauses allow vinci to attach attributes to nodes on the syntax tree and have them passed down to some of the children of a node. We illustrate by rewriting the syntax rules given above:
ROOT = choose No: Number;
NP[No] V[vtdi, third, No, pres] NP PREP/"to" NP %
NP = inherit Nu: Number;
DET[Nu] N[Nu] %
Here, in the ROOT rule, vinci is directed to choose (randomly) a value of type Number, and refer to the choice, whatever it is, by the attribute variable name No. Those with programming experience might think of this as an assignment statement.
This value is attached to the subject NP and also to V. (We have added two further fixed attribute values to V specifying its person and tense.) In the NP rule, vinci is directed to look at the node NP whose children are being constructed, and to pick up the Number value if there is one. This is to be referred to as (assigned to) attribute variable Nu, and is thus passed both to DET and N. So the value chosen and handed to V is now given to the children of NP. Of course, in the second and third instances of NP (the two objects), there is no Number value to inherit, and the inherit clause will be interpreted as a choose clause.
By the way, the attribute variables are understood to be local to the rule in which they occurred. If, say, No were used again anywhere else, it would have no connection with the one in the ROOT rule.
This even applies to the NP rule. If we had used No there instead of Nu, this No would have no connection with the one in ROOT beyond the happenstance that a value which had been assigned to the ROOT No is now being assigned to the NP No. We deliberately used a different name in the example so as not to give the impression that the names had to be the same.
Syntax Transformations
Syntax transformations can be used modify a syntax tree once it has been developed by the context-free rules. Transformation requests are attached to tree nodes while the tree is being generated. Their function is to reorder, add to, duplicate or delete the children of the node.
Extending the previous example, suppose that we want to generate negated sentences: the professor does not give a book to the student. We can do this by using a syntax transformation:
ROOT = NEG: S %
S = choose No: Number;
NP[No] V[vtdi, third, No, pres] NP PREP/"to" NP %
NP = inherit Nu: Number;
DET[Nu] N[Nu] %
NEG = TRANSFORMATION
NP V NP PREP NP: 1 V[2!Number, 2!Person, 2!Tense]/"do"
ADV/"not" 2[-Number, -Person, bare_inf] 3 4 5;
%
Let us deal with a minor point first. In this case, it is the children of ROOT that we need to manipulate. But in simple generation, there is no way to attach a request to the ROOT node. (There is a way when generating sentence clusters.) So we change the context-free rules to insert an extra tree node, S, between ROOT and its children, and place the request on S.
When NEG is carried out, vinci tries to match the left-hand side pattern: NP V NP PREP NP, with the children of S. The match obviously succeeds and the five children (along with any subtrees which hang from them) become associated with the numbers 1 to 5, respectively. The right-hand side now tells vinci how to re- create the children of S. S is to be given seven children: the original 1, an inflected form of the verb "do", the adverb "not", and the original 2 (the verb), 3, 4 and 5. The verb "do" is to acquire the Number, Person and Tense attribute values of 2. The original verb is to have its Number and Person values removed, and its tense replaced by bare_inf to yield "give".
As a result of the transformation, the sentences will now have the negated form.
Could we not have generated the negated sentence directly with context- free rules? Yes, indeed. But in the context of language learning, we may want to generate both a "question", a positive sentence, and its "answer", the negated form. Then the answer must be a transformed version of the question, not an independently generated sentence, otherwise it will not use the same words!
Suppose, with some other set of syntax rules, that the pattern match does not succeed? More generally, the transformation may have several pattern/constructor pairs, and each pattern is tried in turn. If none succeeds, no transformation occurs.
Lexical Field Restrictions
The examples have already shown several kinds of attachment which can be placed on tree nodes by the syntax. Others will be described in due course. One more which will be mentioned here is the lexical field restriction. This is typified by /5=$er, as in the example:
V[vtdi, third, sing, pres]/5=$er
requiring that the word chosen for leaf node V shall have $er in its fifth field. In our French lexicon, this would indicate that the verb was one conjugated by the basic -er paradigm. Several such restrictions may be applied to any leaf node.
Terminal Nodes
When the development of the syntax tree is complete, each leaf node is looked up in the lexicon, and all lexicon entries which match it are identified. One of these is then chosen at random as the word for that node.
In normal circumstances, the name (i.e. metavariable) of a leaf node is that of a word category of the lexicon. Several circumstances, however, including one touched on in a comment above, yield leaf nodes for which this is not true. These will produce errors during the lexicon search.
Several other vinci contexts, such as preselections and lexical transformations, also create "leaf nodes" which lead to lexicon searches, though these have no direct relationship to syntax trees. Sometimes, therefore, we use the term terminal node, though no distinction is implied.
Comment: Anticipating a discussion on Searching at the start of the Manual, we note that when we search a list L of widgets to find which ones match widget P, P need not be an actual widget but may be a widget pattern. Basically, P resembles a widget, but may offer freedom in some of its parts, so that it might match several members of L. So our search in the lexicon for a V to match terminal node V[vtdi, third, sing, pres]/5=$er may select any V which has vtdi, third, sing and pres among its attribute values and has $er in its fifth field.
A terminal node is, in effect, a lexical search pattern. The form given here is one of the ways of writing it. In a few places in vinci, an alternative notation is used.
The Lexicon
The lexicon is usually the largest of the files which describe an object language. It consists of a collection of entries, each corresponding to a word, a phrase, or perhaps a morpheme. (In fact, we often have separate entries for different senses of a word, and must do so if the word falls into more than one word category.) Each entry is a record containing several fields. For the examples earlier, we might have:
"professor"|N|sing||#1|...
"professors"|N|plur||#1|...
"give"|V|vtdi, plur, third, pres||#1|...
"gives"|V|vtdi, sing, third, pres||#1|...
"recommend"|V|vtdi, plur, third, pres||#1|...
"recommends"|V|vtdi, sing, third, pres||#1|...
"to"|PREP|||#1|...
"a"|DET|sing||#1|...
"not"|ADV|||#1|...
"the"|DET|sing, plur||#1|...
It will be noted that a bar symbol terminates each field, that the word category appears in field 2, and that a list of attribute values is in field 3. #1 in field 5 tells something about the morphology of the word, specifically that field 1 contains the word form to be generated. Lexicon entries may have as many fields as the language describer requires, and except for a few at the beginning, vinci places no restrictions on their use. The order of the entries has no significance.
Those familiar with computer algorithms for searching may wonder about the use of binary search, and the need for alphabetical order. It must be emphasized, however, that the vinci lexicon search is not looking for a single entry to match the terminal node, but for all matching entries.
Random choice among the lexicon entries which match a terminal node can be weighted by placing numbers in the fourth field. So, if the entry for "the" is changed to:
"the"|DET|sing, plur|4|#1|...
it will be selected 4 times more often than "a" on average. (If there is no number in the fourth field, 1 is assumed.)
These numbers can be varied temporarily in one of two ways. A further attachment to a terminal node can cause changes to the weight of the entry chosen. So it might be reduced, or even made zero to prevent it being chosen again until the lexicon is reinstalled by vinci. Alternatively, there is a vinci command which takes a terminal node as its parameter and varies the weightings of all lexicon entries which match it.
The Morphology
Our sample lexicon contains separate entries for each form of word, even those words such as "give" and "gives" which are morphologically related. This lengthens the lexicon substantially, especially for languages which are morphologically complex.
To avoid this, vinci offers a comprehensive morphology system which combines rules, tables, lexical fields and fixed strings of letters to produce the inflected forms of an entry. Here the attribute values attached to the terminal node play another role -- it is they which determine the shape of the word generated. The following rule for the regular plurals of nouns provides a simple illustration:
rule noun_reg
sing: #1;
plur: #1 + "s";
%
This states that the singular form of the word is taken from field 1 of the lexicon entry, the plural is obtained from field 1 by attaching "s". The entries for both "professor" and "professors" can be replaced by:
"professor"|N|Number||$noun_reg|...
where field 5 now directs vinci to generate the appropriate word using rule noun_reg. Different rules are needed for other "regular" plurals, such as those which add -es or change a final -y to -ies.
Lexical Pointers and Indirections
Returning again to the lexicon, we introduce a further feature: the lexical pointer.
Lexical pointers allow words in a lexicon to "point at" other entries related to them either semantically or by derivation or in some other way. For example, the language describer might want words to point at synonyms or antonyms, or perhaps to simpler words from which they are derived. Consider some entries in a lexicon relating to flowers:
"Stella D'Oro"|N|varname||#1||gen: "daylily", col: "yellow"/ADJ|
"daylily"|N|genus||#1||||bulb_type: "tuber"|
"yellow"|ADJ|colour||#1||
Here gen: "daylily", col: "yellow"/ADJ are two lexical pointers in field 7 of a flower variety. We may guess that the former points to the genus, "daylily", found elsewhere in the lexicon, the latter to its colour, "yellow". The tags, gen and col, chosen by the describer, indicate the nature of the relationship. Choice of field is also a matter for the describer. The presence of /ADJ on the second indicates a different word category from entry itself. Incidentally, this example shows the potential for using a lexicon as a database.
vinci makes use of the relationship by way of an indirection attached to a terminal node; for example:
N[varname]/@7: gen
The indirection (so called because it causes a lexicon entry to be accessed indirectly) tells vinci first to choose a variety name, then to obtain the related entry, its genus. Several indirections can be attached to a node; for example:
N[varname]/@7: gen/@9: bulb_type
This time, after obtaining the genus related to variety name, vinci is told to get the bulb type related to the genus.
(Not yet implemented) A second access mechanism, a reverse indirection, is the exact opposite of an indirection. For a lexicon entry W, rather than asking for a word X which W is pointing at, it asks for a word Y which is pointing at W.
Lexical Transformations
We have mentioned that a secondary function of vinci is to transform parts of the object language lexicon to create new words, based on rules known as lexical transformations. A typical example in English to create manner adverbs from descriptive adjectives by adding -ly might be:
?|ADJ|descriptive|_makes_ [#1 + "ly"]|ADV|!6||#1|
(We ignore cases such as "speedy"/"speedily", where the end of the adjective needs adjustment.)
The left-hand side of the rule selects lexicon entries with word category ADJ and attribute value descriptive. The symbol ? in the first field is a don't care symbol or wildcard, which matches anything found in the first field of the entry. An empty field requires the corresponding field of the lexicon entry to be empty too. The form of the left-hand side parallels that of a lexicon entry. Fields not specified (above the third here) are assumed to be "don't care".
The right-hand side is a constructor, telling vinci field by field how to make a new word. The first field is within [ ], which asks for the field to be built by the morphology process described earlier. In this case, vinci is asked to take the first field of the chosen ADJ and add "ly". The third constructor field starts with an exclamation point, and tells vinci to copy field 6 of the ADJ as the third field of the new word. The second, fourth and fifth fields of the constructor have neither [ ] nor an exclamation point and are simply copied as fields of the new word. So, if one of the matching lexicon entries is:
"quick"|ADJ|descriptive||#1|manner|
the derived entry will be:
"quickly"|ADV|manner||#1|
Note that the left-hand side is, of course, our old friend, the terminal node. It is a lexical search pattern which selects entries from the lexicon for transformation. In this context, it is expressed in a different form. Conversely nodes such as:
V[vtdi, third, sing, pres]/5=$er
V/"do"
are equivalent to:
?|V|vtdi, third, sing, pres||$er|
"do"|V|
More generally, vinci allows multiple left-hand sides, so that lexical entries such as "ice-breaker" and "paper-cutter" can be created from their constituent parts.
vinci allows lexical transformations to be applied systematically to create new lexical entries from an existing lexicon.
Inverted Lexical Transformations
The concept of inverted lexical transformations is closely related to the previous one. Rather than enlarging the lexicon by systematically deriving new entries, however, an inverted transformation allows vinci to create new words during sentence generation, as they are needed.
These transformations resemble lexical entries, but have three parts and are placed in the lexicon. If one of them is chosen for a leaf node, it causes vinci to begin a secondary search for a different word, which is then transformed to the word originally required. Suppose, for example, that an English lexicon has few adverbs ending in -ly, but has the inverted lexical transformation:
_ilt_ |ADV|manner| _lsp_ ?|ADJ|descriptive| _rhs_ [#1 + "ly"]|ADV|!6||#1|
To the lexicon search process, the start of this looks like an ADV entry, and it may be chosen as such. Its choice, however, triggers a secondary search for an ADJ, which is then converted to the desired ADV. As for lexical transformations, there may be more than one _lsp_ component, and the secondary search/searches may themselves choose inverted lexical transformations, leading to tertiary searches, and so on.
Generating Sentence Clusters
Earlier, we mentioned a language learning application which required both "questions" and matching "answers". For example, we might want to exercise a learner in the negation of English sentences, by presenting random positive forms and requesting the negated ones. Thus we would like vinci to generate:
the fish recommends a cousin to the hostess
and the corresponding answer:
the fish does not recommend a cousin to the hostess
The scenario anticipates that the former will be displayed, the latter concealed for subsequent comparison with the student response.
vinci allows the generation of clusters of related sentences, as shown in the following example adapted from the earlier syntax:
ROOT = choose No: Number;
NP[No] V[vtdi, third, No, pres] NP PREP/"to" NP %
NP = inherit Nu: Number;
DET[Nu] N[Nu] %
NEG = TRANSFORMATION
NP V NP PREP NP: 1 V[2!Number, 2!Person, 2!Tense]/"do"
ADV/"not" 2[plur, pres] 3 4 5;
%
QUESTION = ROOT %
ANSWER = NEG: ROOT %
Once again, ROOT yields the positive sentences. (We no longer need the intervening tree node S because in this context, NEG can be placed on ROOT itself. In fact, S would get in the way, because it would be the children of S, rather than ROOT, which had to be transformed.) This time, however, we see two further root nodes, QUESTION and ANSWER, which are similar to ROOT, in that they are the precursors of generated sentences.
When the syntax tree for ROOT has been expanded by context- free rules, vinci proceeds to expand QUESTION and ANSWER in the same way, but with one variation: when it encounters ROOT on the right-hand side of a rule, it does not re-expand it. Instead, it places a copy of the existing ROOT tree on the QUESTION or ANSWER tree. In our example, the QUESTION tree will be a copy of the ROOT tree; the ANSWER tree will be a copy, but with NEG: attached to the ROOT node.
Why do we need a QUESTION tree, rather than using ROOT itself as the question? Because, when any of the additional tree roots is present in the syntax, the ROOT tree does not yield a sentence of its own. It merely acts as a common subsidiary for the others.
The Analysis of Student Errors
Developing the language learning scenario presented in the previous section, we generate a "question", present it to a student, and await a response. When this has been entered, we might compare it with the concealed (i.e. correct) response, display a right/wrong message, along with the right answer if necessary, and keep a tally of the student's score.
vinci, however, incorporates a much more sophisticated and powerful comparison mechanism. We will not give details in this Overview. Suffice it to say that it can report insertions, omissions and differences in the order of words, along with apparent variations of morphology, phonology and spelling within words. Details can be found in:
Levison, Michael; Lessard, Greg; Danielson, Anna Marie; Merven, Delphine. From Symptoms to Diagnosis. In CALL -- The Challenge of Change, (Cameron, Keith; ed.), Exeter: Elm Bank Publications, 2001, pp. 53-59.
and also in the Manual.
Preselection
Preselection provides a metaphorical blackboard on which a user may write choices to affect sentence development. The choices may relate to structure or may involve lexical selection -- selection which takes place before the syntax tree is developed. The syntax rules can look at the blackboard with the selected words, either to make some of its choices, or perhaps to obtain some of the information needed to build the sentence: whether a noun is masculine or feminine, whether a French adjective precedes or follows its noun, and so on.
In our desire to express the fact that the ever-generous professor has made the customary donation to undeserving student(s), we may add a preselection rule to the syntax, modifying the context-free rules to make use of it:
PRESELECT
agent: N/"professor";
action: V[give];
theme: N/"book";
beneficiary: N/"student"
%
ROOT = NP[agent, sing] V[third, sing, pres]/_pre_ action
NP[theme] PREP/"to" NP[beneficiary] %
NP = inherit Fn: Function;
inherit Nu: Number;
DET[Nu] N[Nu]/_pre_ Fn
%
The preselection rule shown here has four clauses, each consisting of a tag and a right-hand side. The tags: agent, theme, beneficiary and action, are attribute values belonging to an attribute type: Function. The right-hand sides are terminal nodes (not associated with any tree) which lead to lexical choices. In three of the clauses, there is a mandated choice; in the second, any verb having the attribute value give may be picked: "donate", "give", "hand over", ...
In the ROOT rule, V has an attachment in the form of a _pre_ phrase. This is analogous to a mandated choice, directing that the word used for V must be the one preselected for action. The _pre_ phrase in the NP rule is similar, but uses as preselection tag an attribute value inherited from its parent. So, when NP[agent, sing] is developed, the NP rule inherits agent, and uses "professor" as its lexical choice; NP[theme] and NP[beneficiary] use "book" and "student", respectively.
The two context-free rules can, of course, generate any sentence involving a direct and an indirect object; only the PRESELECT rule need change.
Global and Local Preselections
Preselections may be either global or local. There is no difference in form; they differ only in the time at which the lexical choices are made. Local preselections are made (or re-made) for each sentence; global preselections persist for as long as the user wishes.
To illustrate, consider the generation of a classical fairy tale, comprising a number of sentences. A global preselection might be:
PRESELECT =
twit: N[person, male, rich]/14=daughter;
hero: N[person, male, brave, handsome];
victim: N/_pre_ twit/@14: daughter;
villain: N[person, evil];
goodfairy: N[person, female, good, supernatural];
magicobj: N[physical_obj, magic]
%
This amounts to a dramatis personae. It selects a twit: a rich male person, with daughter as part of field 14, presumably a lexical pointer tag. To choose the victim, vinci picks up the lexicon entry selected for the twit, then follows an indirection to obtain the twit's daughter. And so on. Obviously, these choices must persist throughout the story.
During the story, the goodfairy gives the hero a magicobj. For this sentence, we use a local preselection:
PRESELECT =
vtdi;
action: V[give];
agent: N/_pre_ goodfairy;
beneficiary: N/_pre_ hero;
theme: N/_pre_ magicobj
%
very like the one in the previous section, except that it obtains its agent, theme and beneficiary by reference to the global choices. The extra clause, vtdi, controls syntactic structure rather than lexical choice. It directs vinci to choose syntax for a vtdi-sentence, since the context-free rules must now be capable of generating many kinds of sentence.
Semantic Expressions and Semantic Transformations
Semantic expressions use simple functional forms to represent the meaning of sentences, allowing a text (say, the fairy story) to be expressed as the sequence:
...
exists(villain)
kidnap(villain, victim)
...
seek(hero, goodfairy)
give(goodfairy, hero, magicobj)
...
exists(X) is expected to introduce the person X, amplifying this with a description obtained, perhaps, from X's lexicon entry. give() might be our favorite example.
This has been an area of research by our students and by us in the past few years, and only a limited form is implemented in the current vinci version. Fuller details can be found in:
Donald, Matthew C., A Metalinguistic Framework for Specifying Generative Semantics, thesis submitted for the degree of Master of Science, Queen's University, Kingston, Ontario, 2006.
The current implementation provides for semantic transformations which convert semantic expressions into preselections. The relationship between give(goodfairy, hero, magicobj) and the earlier local preselection is fairly obvious. As the expressions themselves include no reference to the syntax of any language (and recall that the attributes are merely names, not meaningful words of English), we strive to make them language-independent, so as to form the basis for multi-lingual generation. The expressions above have, in fact, given rise to fairy stories both in English and French.